Hash table
Our last important data structure is the hash table. It’s very useful when you want to quickly look for values. Moreover, understanding the hash table will help us later to understand a common database join operation called the hash join. This data structure is also used by a database to store some internal stuff (like the lock table or the buffer pool, we’ll see both concepts later)
The hash table is a data structure that quickly finds an element with its key. To build a hash table you need to define:
- a key for your elements
- a hash function for the keys. The computed hashes of the keys give the locations of the elements (called buckets).
- a function to compare the keys. Once you found the right bucket you have to find the element you’re looking for inside the bucket using this comparison.
A simple example
Let’s have a visual example:
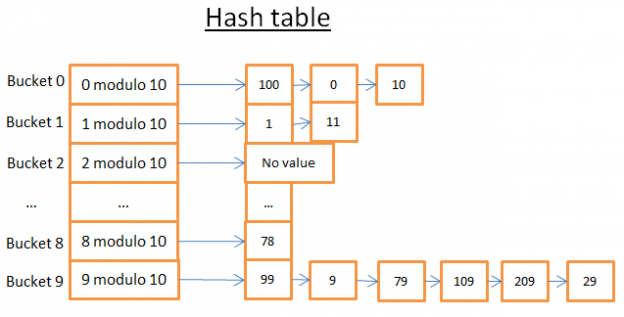
This hash table has 10 buckets. Since I’m lazy I only drew 5 buckets but I know you’re smart so I let you imagine the 5 others. The Hash function I used is the modulo 10 of the key. In other words I only keep the last digit of the key of an element to find its bucket:
- if the last digit is 0 the element ends up in the bucket 0,
- if the last digit is 1 the element ends up in the bucket 1,
- if the last digit is 2 the element ends up in the bucket 2,
- …
The compare function I used is simply the equality between 2 integers.
Let’s say you want to get the element 78:
- The hash table computes the hash code for 78 which is 8.
- It looks in the bucket 8, and the first element it finds is 78.
- It gives you back the element 78
- The search only costs 2 operations (1 for computing the hash value and the other for finding the element inside the bucket).
Now, let’s say you want to get the element 59:
- The hash table computes the hash code for 59 which is 9.
- It looks in the bucket 9, and the first element it finds is 99. Since 99!=59, element 99 is not the right element.
- Using the same logic, it looks at the second element (9), the third (79), … , and the last (29).
- The element doesn’t exist.
- The search costs 7 operations .
A good hash function
As you can see, depending on the value you’re looking for, the cost is not the same!
If I now change the hash function with the modulo 1 000 000 of the key (i.e. taking the last 6 digits), the second search only costs 1 operation because there are no elements in the bucket 000059. The real challenge is to find a good hash function that will create buckets that contain a very small amount of elements.
In my example, finding a good hash function is easy. But this is a simple example, finding a good hash function is more difficult when the key is:
- a string (for example the last name of a person)
- 2 strings (for example the last name and the first name of a person)
- 2 strings and a date (for example the last name, the first name and the birth date of a person)
- …
With a good hash function,the search in a hash table is in O(1).
Array vs hash table
Why not using an array?
Hum, you’re asking a good question.
- A hash table can be half loaded in memory and the other buckets can stay on disk.
- With an array you have to use a contiguous space in memory. If you’re loading a large table it’s very difficult to have enough contiguous space .
- With a hash table you can choose the key you want (for example the country AND the last name of a person).
For more information, you can read my article on the Java HashMap which is an efficient hash table implementation; you don’t need to understand Java to understand the concepts inside this article.